Reference Caption
a guy doing a jump with his skateboard
Candidate Caption
a boy on a skateboard doing a trick
Pearl Score
0.86
Human Score
0.91
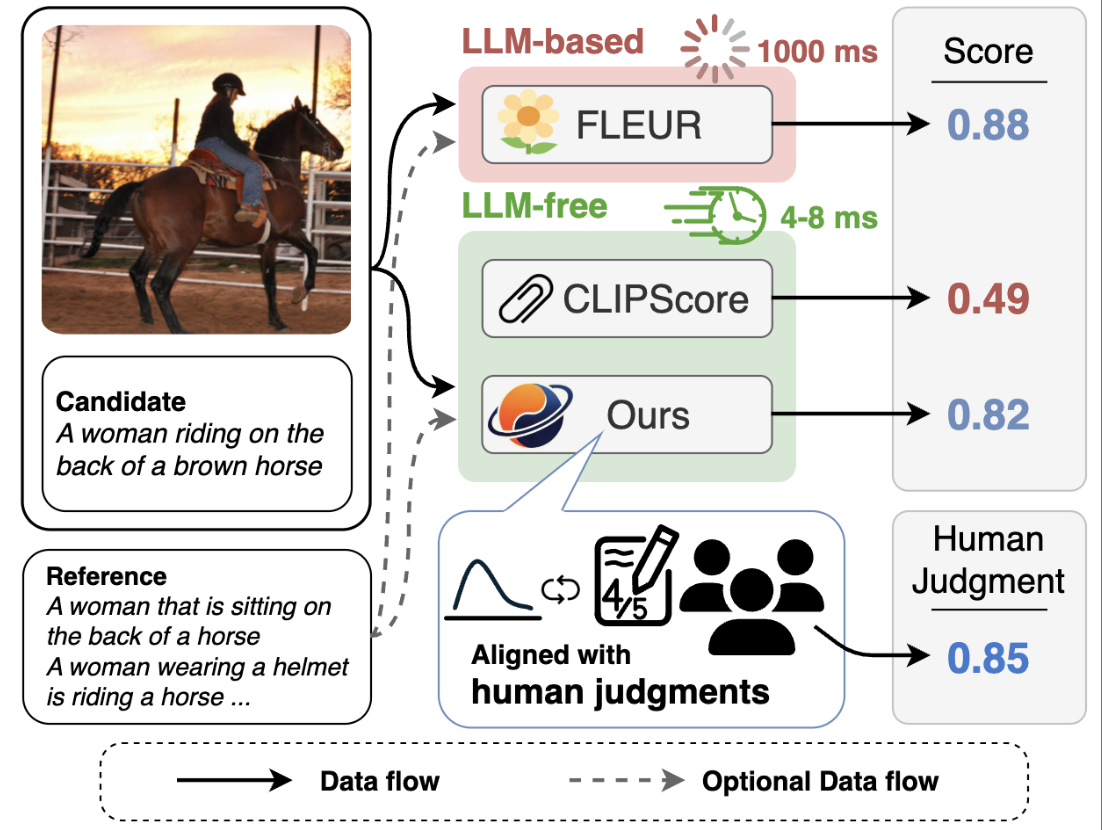
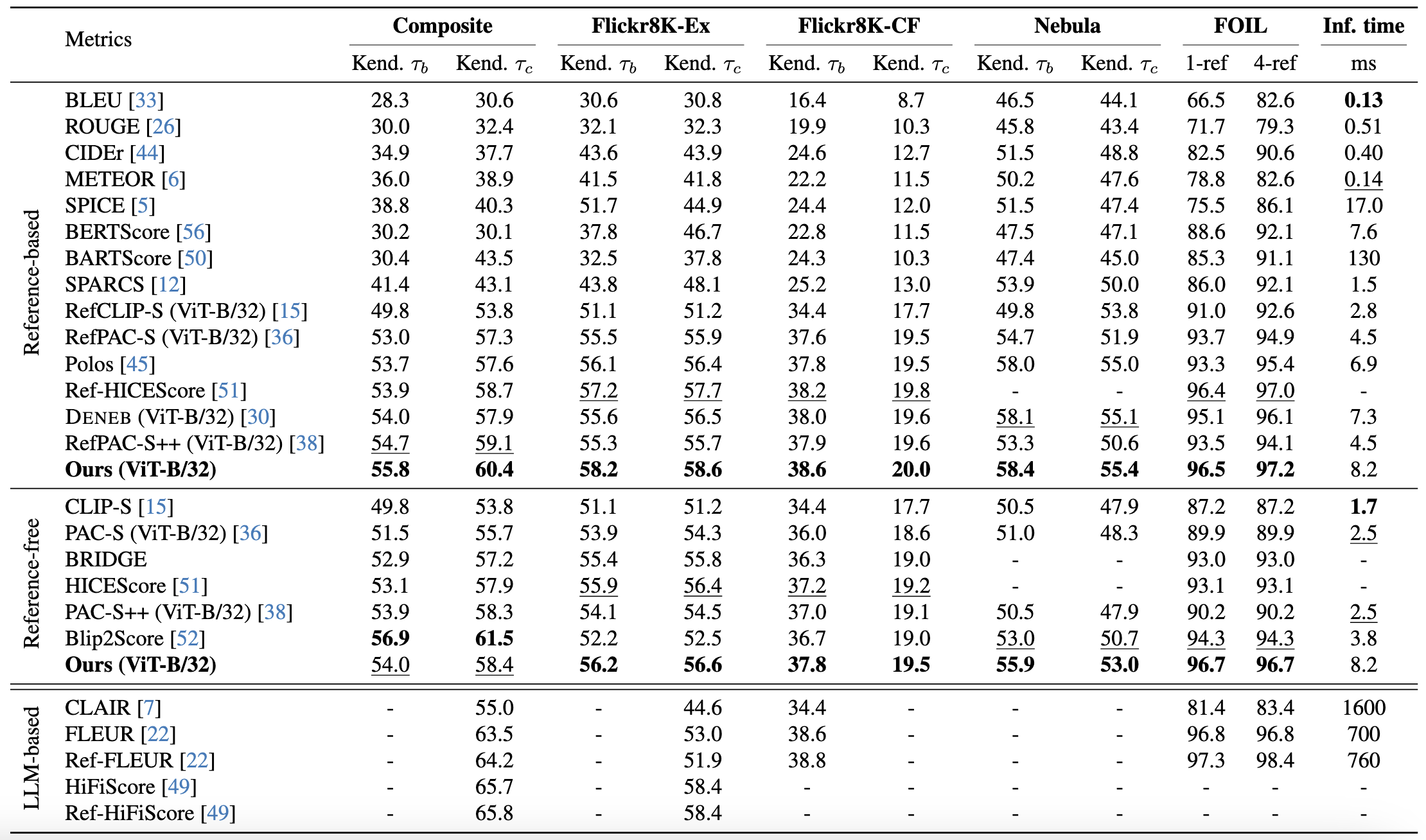
We focus on the automatic evaluation of image captions in both reference-based and reference-free settings. Existing metrics based on large language models (LLMs) favor their own generations; therefore, the neutrality is in question. Most LLM-free metrics do not suffer from such an issue, whereas they do not always demonstrate high performance. To address these issues, we propose Pearl, an LLM-free supervised metric for image captioning, which is applicable to both reference-based and reference-free settings. We introduce a novel mechanism that learns the representations of image--caption and caption--caption similarities. Furthermore, we construct a human-annotated dataset for image captioning metrics, that comprises approximately 333k human judgments collected from 2,360 annotators across over 75k images. Pearl outperformed other existing LLM-free metrics on the Composite, Flickr8K-Expert, Flickr8K-CF, Nebula, and FOIL datasets in both reference-based and reference-free settings.
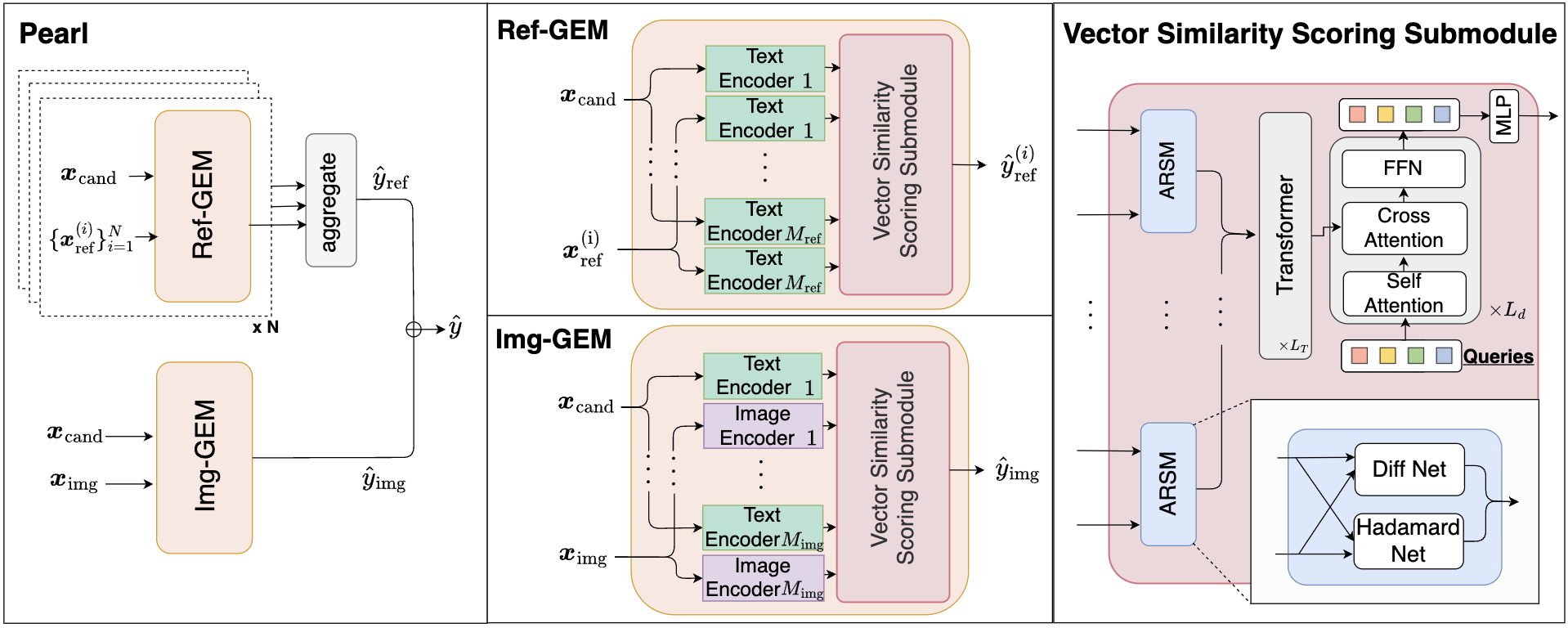
Pearl is designed to evaluate image captioning models efficiently.
Pearl achieves robust performance in both reference-based and reference-free settings.
Pearl demonstrates state-of-the-art performance on standard benchmarks including Composite, Flickr8K-Expert, Flickr8K-CF, Nebula, and FOIL. Notably, in the reference-based setting, Pearl achieves high correlation with human judgments while maintaining an inference time of only 8.2ms per sample.
Evaluating captions with reference captions available
 1
1
 2
2
 3
3
 4
4
 5
5
a guy doing a jump with his skateboard
a boy on a skateboard doing a trick
Pearl Score
0.86
Human Score
0.91
comming soon




